How Google Analytics Tracks The Traffic Sources On Your Website
January 31st, 2016
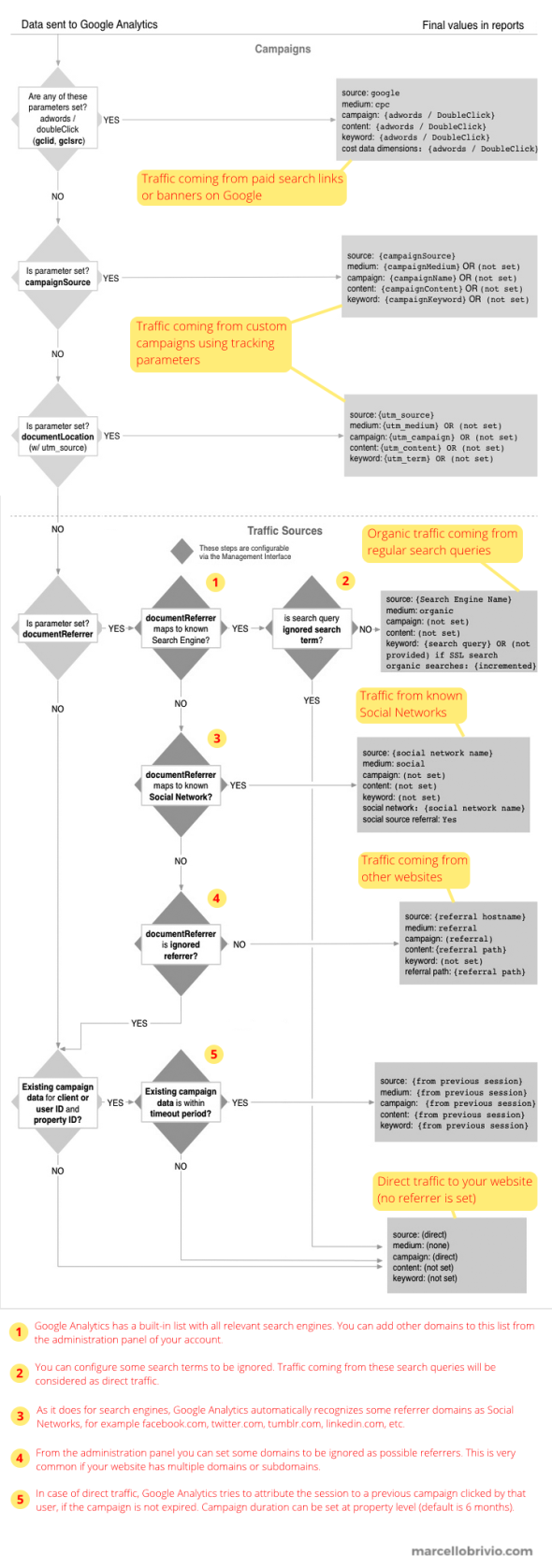
Google Analytics is probably the most popular and widspread web analytics tool on the market. One of its core features is giving clear and detailed insights about where your visitors are coming from. This is done in the “Acquisition” panel, and it represents one of the most important dashboard for any web marketer.
Basically, here you can discover how many of your visitors came to your website directly typing your URL in their browser or clicking on a bookmark (this is called “direct” traffic), how many found your pages through a search query on Google (the “organic” traffic), how many are coming from links posted on social networks, etc.
A more advanced use of the “Acquisition” dashboard requires customized links: adding a set of special “UTM” parameters to your URL allows you to create a specific tracking for any campaign, for example email newsletters, banners, blog posts and any other digital marketing initiative involving a link to your pages. If you pay attention while browsing the Web, you’ll probably notice a lot of URLs like the following example:
http://link.com/?utm_campaign=spring&utm_medium=email&utm_source=newslet2So, Google Analytics has to manage a lot of possible traffic sources. The following flow chart, taken from its official documentation, explains how it does the source recognition and which is the priority.